[Paper Explained] From Categories to Classifier: Name-Only Continual Learning by Exploring the Web

Introduction
Continual Learning (CL) is pivotal for developing AI systems that adapt over time. Traditionally, CL relies heavily on annotated datasets, which are costly and time-consuming to produce. For example, annotating 30K samples for the CLEAR10 dataset took over a day and cost $4,500. This becomes a significant bottleneck, especially for businesses like Amazon or Fast Fashion brands that need to continually update their models to reflect inventory changes or consumer trends.
This brings us to the concept of name-only continual learning, a scenario where, at each timestep, the learner is only provided with the class names, not annotated datasets. The challenge is to adapt the classification model to these new classes quickly, leveraging uncurated webly-supervised data. This approach can dramatically speed up the updating process of classifiers, making it possible to adapt to new trends almost in real-time.
Countries like Japan have started allowing the use of online data for training AI models, regardless of copyright status. This opens up new possibilities for leveraging the vast amount of data available on the internet, which is continually updated with new images. By tapping into this resource, we can query and download relevant images to train our models, circumventing the need for manual annotation.
In this blog post, we explore how reliable uncurated webly-supervised data is, how it compares to the latest name-only classification approaches, and whether it can be effectively used in various continual learning settings.
Paper: https://arxiv.org/abs/2311.11293
Name-Only Classification: Problem Formulation
In name-only classification, the task is to learn a model where the only information provided is the class categories (and possibly description about the class categories).
The Task: Given a list of class names ONLY — do something to learn a classifier.

Unlike zero-shot learning, which doesn’t allow using examples from the target categories, name-only classification allows using publicly available data and models that do not overlap with the test set. Hence typical approaches to tackling this task have been either using LAION5B image retrieval OR generative models to generate samples of the target classes. However each of those have downsides:
(1) LAION5B Retrieval: Retrieve samples from a big corpus of static dataset (of text-image pairs) such as LAION5B that match a “target class name”.

(2) Diffusion Models: Using a generative model generate images of the class-names at hand.

Our Proposed Solution: Instead of relying of static datasets such as LAION5B for retrieval or Diffusion Models for generating samples of the target classes -> Use the web!! In the end most open source diffusion models are trained on LAION5B and LAION5B is constructed from the web, hence the web is the bigger set!
Why the web?
- The web is dynamic and adapts to emerging trends (e.g. COVID)
- The web offers a cheap source of data with weak annotations.
- The web offers a scalable solution.
- Recent laws have permitted the use of web data for classification tasks.
Extending to Continual Learning: This setup can be easily extended to name-only continual learning, where new categories or domain shifts are introduced over time, and the model must be updated to incorporate these changes without access to a labeled training dataset.
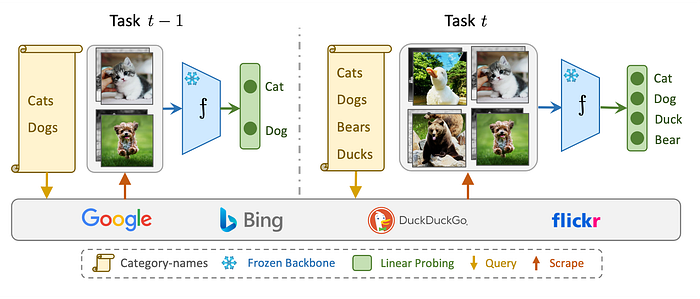
Our Approach: Categories to Classifier By Exploring the Web
Given the constraints of name-only continual learning, our approach, dubbed C2C (Categories to Classifier), consists of two main steps:
Step 1: Querying and Downloading Uncurated Webly-Supervised Training Data:
- After being presented with a list of class names we refine our web queries by adding auxiliary suffixes to class names to ensure relevance and implement safeguards against explicit content.
Example: instead of searching for “Snapdragon” which might be confused with the Snapdragon CPUs we explicitly add an auxiliary suffix “flower” hence querying the web for “Snapdragon Flower” when flower object is intended.
- Using the refined queries, web-scrapping is performed to collect samples from four engines: Flickr, DuckDuckGo, Bing and Google. Scraping is performed fully on CPU nodes.
Step 2: Classifier Training:
- Once we have uncurated webly-supervised data the next step is to train a classifier. Several approaches ranging from training a linear layer, an MLP and full fine-tuning are experimented with.
In short this approach leverages the scalability of the internet to gather training data, significantly reducing the time and expense associated with manual annotation.
Experimental Setup and Findings
Datasets and Models: We selected a range of fine-grained classification benchmarks, such as FGVC Aircraft, Flowers102, OxfordIIITPets, Stanford Cars, and BirdSnap. These datasets pose a significant challenge, given their need for expert-level annotations. We utilized a ResNet50 MoCoV3 model as our backbone, experimenting with both Linear Probe, MLP Adapter and Full Finetuning.
Key Findings: Our experiments revealed that, in many cases, models trained on uncurated webly-supervised data achieved comparable or superior accuracy to those trained on manually annotated datasets. This improvement was particularly notable when using the MLP-Adapter, indicating the potential of webly-supervised data to match or even exceed the quality of expert annotations. The scalability of web data was a crucial factor, with our datasets being significantly larger than the manually annotated ones.
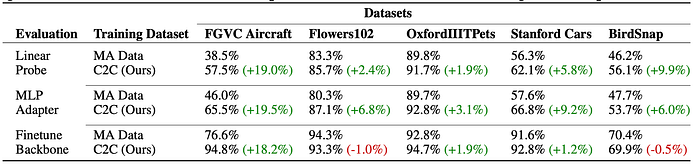
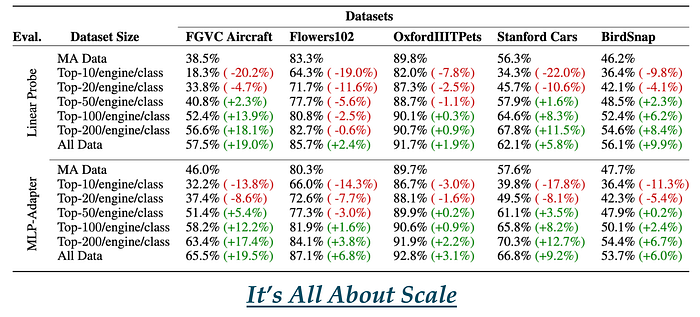
Why Does it Work? It’s All About The Scale !
The scale of the webly-supervised datasets, being 15 to 50 times larger than their manually annotated counterparts, played a pivotal role in performance gains. By adjusting the amount of data retrieved from the web (limiting to top-k images), we observed that the quantity of data directly influenced model accuracy. This scalability, achievable at minimal cost, underscores the efficiency of using webly-supervised data for training models. Note that this scalability is not achievable with Diffusion Models due to computation cost and with LAION5B due to it being a static dataset with limited number of samples per class.
Continual Webly-Supervised Learning
In this section, we extend the application of uncurated webly-supervised data to various continual learning scenarios. We aim to demonstrate the adaptability of our approach in the face of class-incremental, domain-incremental, and time-incremental challenges.
Experimental Details
Scenarios and Datasets: We conducted experiments across three distinct continual learning setups:
- Class-Incremental Learning with CIFAR100: We partitioned CIFAR100 into ten timesteps, introducing ten new classes at each step.

- Domain-Incremental Learning with PACS: Utilizing the PACS dataset, we navigated through four domains (Photos, Art, Cartoon, Sketches), adjusting to the visual style of each.
- Time-Incremental Learning with CLEAR10: By incorporating timestamps, we created a more dynamic learning environment, reflecting real-world class evolution.

Training and Evaluation: For each scenario, we compared the performance of our webly-supervised approach against models trained on manually annotated data. Despite the inherent advantages of manually annotated datasets, our webly-supervised data closely matched their performance, showcasing the potential of our method in a continually evolving landscape.
Results and Insights
Our findings underscore the efficacy of webly-supervised data in the three studied continual learning settings.

The results are very impressive! But why don’t we outperform manually annotated data?
1. The domain shift between webly-supervised data and continual learning datasets studied is significant.
2. The scale of our webly-supervised data is not much larger than the manually annotated ones in the CL setting.
Domain Shift (In Short):
- Problem: In CIFAR100 the domain shift is image quality due to CIFAR100 being 32x32 vs web data being of higher quality.
Solution: Downsample the web images to 32x32. - Problem: In PACS domain shift is one particular domain called sketches where in PACS it refers to quick doodles where as in web scraped data its actual sketches.
Solution: Query for quick doodles. - Problem: In CLEAR10 domain shift is one particular class, where buses refer to interiors of buses in the curated dataset but web samples had exteriors of buses.
Solution: Query for interiors of buses.
Extras
- EvoTrends Benchmark: To further validate our method, we introduced the EvoTrends dataset, which represents a real-world challenge of adapting to trending products over two decades. Our approach successfully navigated this dataset, quickly adapting to new trends and outperforming baseline models like zero-shot CLIP in classification accuracy.
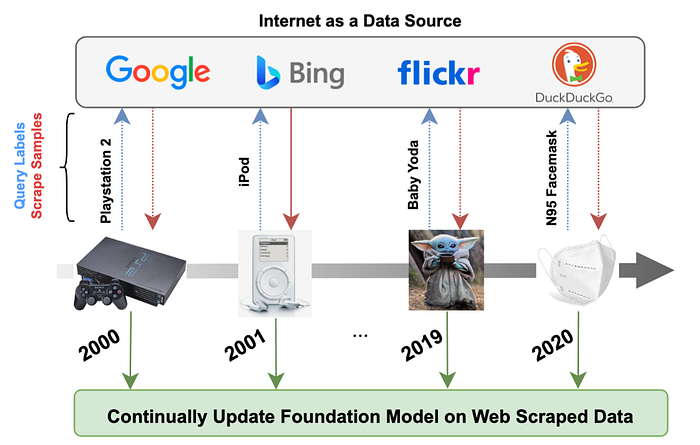
2. Extra Experiments and Key Conclusions:
- Does The Network Architecture Matter: Nope!
- Does Automated Dataset Cleaning Help ? Nope!
- Which Engine is Best? Flickr (in most cases but not always).
- Which Engine is Worst? Google (in most cases but not always)
- Does Class Balancing Help? Nope!
- Different Budgets? Higher budget gap grows, Lower Budget gap shrinks.
Conclusion
Our exploration into name-only continual learning reveals a promising avenue for reducing the dependency on costly and time-consuming manual annotation. By leveraging uncurated webly-supervised data, we can maintain high performance levels while significantly reducing annotation costs. This approach opens up new possibilities for rapid model adaptation in continually evolving environments.
Future work could explore extending this setting to include test-time adaptation using the web, tackling online continual learning challenges, and addressing the limitations of data collection in niche domains. Our findings underscore the vast potential of webly-supervised learning in the continual learning landscape, offering a more efficient and scalable alternative to traditional methods.
